



Das Crawl-Budget ist die Kapazität, die Suchmaschinen einer Website zum Crawlen zur Verfügung stellen.
Google weist diese Kapazitäten automatisch jeder Domain zu. Dieser Automatismus funktioniert jedoch nicht immer hundertprozentig korrekt, sodass manche Webseiten nicht genügend Crawl-Budget erhalten.
In diesem Artikel erfährst du, wie du herausfinden kannst, ob dein Standort davon betroffen ist und was du dagegen tun kannst.
Das Wichtigste in Kürze
- Über das Crawl-Budget muss man sich erst Gedanken machen, wenn die Website mehr als 10.000 URLs hat.
- Beim Crawl-Budget geht es nicht in erster Linie um die Anzahl der URLs, sondern um die Zeit, die Google für das Crawlen einer Website aufwenden muss.
- SEOs können das Crawl-Budget nicht direkt, sondern nur indirekt beeinflussen.
Inhalt
So vergibt Google Crawl Budget an Websites
Wie bereits erwähnt, vergibt Google das Crawl Budget automatisch an Websites. Google stellt auch keine Informationen zur Verfügung, über wie viel Crawl Budget eine Website verfügt.
Was jedoch bekannt ist: Das Budget wird in Queries per Second vergeben (Quelle). Das ist die Anzahl der Anfragen, die der Googlebot in einer Sekunde an eine Website stellen kann. Eine schnelle Website ist also auch hier von Vorteil.
Google versucht bei der Budgetvergabe die richtige Balance zwischen schnellem Crawlen und dem Schutz der Website vor Überlastung zu finden. Denn wenn Google zu viel und zu schnell crawlt, kann es passieren, dass die gecrawlte Website „abgeschossen“ wird und nicht mehr erreichbar ist.
In der Regel reduziert Google das Crawling jedoch bereits vorher. Wenn festgestellt wird, dass die Ladezeiten der gecrawlten Website langsamer werden, reduziert Google das Crawling.
💡 Was passiert, wenn eine Website durch Crawling überlastet ist?
Wenn eine Website überlastet ist, sendet der Server den http-Statuscode 503 (Service Unavailable) oder 429 (Too Many Requests) und Google stoppt das Crawling, bis die Seite wieder verfügbar ist.In der Zwischenzeit können aber auch keine menschlichen Nutzer auf die Website zugreifen, was schnell zu hohen Umsatzeinbußen führen kann. Daher crawlt Google eher zu wenig als zu viel.
Die Rolle von Verlinkungen und Aktualisierungen
Neben der Ladezeit und der Serverkapazität spielt auch die Häufigkeit, mit der eine Website aktualisiert wird, eine Rolle. Publisher Websites, die mehrere neue Artikel pro Tag veröffentlichen, können damit rechnen, von Google mehr Ressourcen zur Verfügung gestellt zu bekommen.
Ein weiterer Faktor ist die Verlinkung der Inhalte. Google möchte nur Inhalte crawlen und indexieren, die von den Nutzern nachgefragt werden. Ein Kriterium, das dabei eine wichtige Rolle spielt, ist die Verlinkung der Inhalte. Je häufiger ein Inhalt verlinkt ist, desto höher ist die Wahrscheinlichkeit, dass Google ihn zeitnah crawlt.
Wie du erkennst, ob deine Seite ein Problem mit der Crawling-Kapazität hat
Häufig wird das Crawling-Budget verdächtigt, wenn neue Inhalte nicht sofort indexiert werden. Verwirrend ist zudem, dass Google weder die Crawl-Kapazität einer Website angibt, noch mangelndes Crawl-Budget als Ursache für nicht indexierte Inhalte nennt.
Für kleine Websites kann meist Entwarnung gegeben werden: Ein zu geringes Crawl-Budget ist in den meisten Fällen ein Problem größerer Websites mit mehr als 10.000 URLs. Aber auch Seiten, die viele URLs im Search Console Report „Gefunden – derzeit nicht indexiert“ haben, können ein Problem mit dem Crawl-Budget haben.
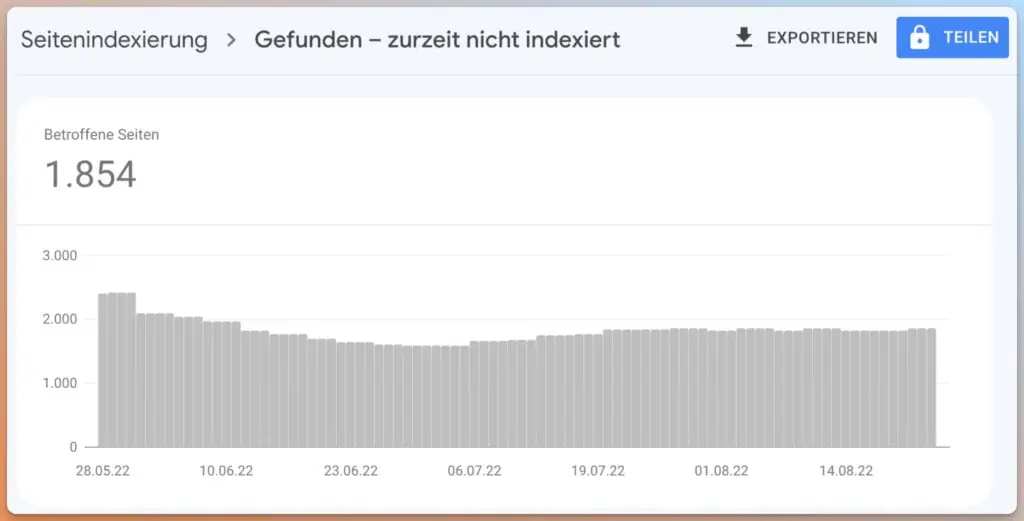
Wenn einer der folgenden Punkte auf deine Website zutrifft, hast du möglicherweise ein Problem mit dem Crawl-Budget:
- Website größer als 10.000 URLs
- Seite wird häufig aktualisiert, die Seiten jedoch nicht gecrawlt
- Die Website ist langsam
Um Letzteres auszuschließen, gibt es in der Search Console unter Einstellungen > Crawling-Statistik Diagramme, die zeigen, wie sich die Menge der gecrawlten Daten im Verhältnis zur Reaktionszeit der Website entwickelt hat.
Stellt man hier fest, dass die Reaktionszeit des Servers mit der Anzahl der abgerufenen Inhalte steigt, kann dies dazu führen, dass Google das Crawling aufgrund von Serverüberlastung reduziert. Hat sich der Server wieder erholt, erhöht Google die Frequenz in der Regel wieder.
Die Search Console zeigt auch an, welcher Anteil der Crawling-Ressourcen auf welchen Dateityp (HTML, JavaScript, PDF usw.) entfällt. Im Folgenden finden Sie einige Tipps zum Umgang mit JavaScript- und CSS-Dateien im Zusammenhang mit Crawling-Ressourcen.
💡 Welche Ressourcen fallen in das Crawl Budget?
Jede URL, auf die innerhalb der Website verwiesen wird, wird von Google gecrawlt und wirkt sich auf die Crawling-Ressourcen aus. Dazu gehören auch PDF-Dateien, JavaScripts, CSS-Dateien und API-Aufrufe.
Wie sich das Crawling auf diese Ressourcen verteilt, wird ebenfalls in den Crawl-Statistiken in der Search Console angezeigt.
Lösungsmöglichkeiten für ein optimiertes Crawling
Wenn sich der Verdacht erhärtet, dass deine Website von Google nicht ausreichend gecrawlt wird, gibt es einige Möglichkeiten, Abhilfe zu schaffen.
- Sorge für eine schnelle Website und ausreichend Serverkapazität. Dies ist besonders wichtig, wenn du in der Search Console siehst, dass der Googlebot lange braucht, um Ressourcen von deiner Website zu laden.
- Vermeide unnötige Weiterleitungen. Jede Weiterleitung auf deiner Website ist eine zusätzliche URL, die gecrawlt werden muss. Interne Links auf der Website sollten daher nicht auf URLs verweisen, die eine Weiterleitung auslösen.
- Achte auf Qualität und Links. Qualität ist zwar kein offizielles Kriterium für die Vergabe von Crawling-Kapazitäten, aber wenn es um die Indizierung von URLs geht, spielt es eine große Rolle, ob diese von Google als hilfreich eingestuft werden. Es sollte auch darauf geachtet werden, dass neue Inhalte immer gut verlinkt sind, z.B. von der Startseite aus.
- Verwende korrekte Status Codes. Gelöschte Seiten sollten einen http-Statuscode 410 erhalten, der im Gegensatz zu 404 sicherstellt, dass die Seite nicht mehr (so häufig) gecrawlt wird. Gleiches gilt für Redirects, hier wird ein 301 von Google schneller verarbeitet als ein 302. Auch wenn die Search Console im Index Coverage Report viele Soft 404 Fehler anzeigt, besteht Handlungsbedarf: Diese werden von Google nicht als 404 behandelt und belasten somit das Crawl Budget.
- Konsolidiere doppelte oder ähnliche Inhalte. Duplicate Content kann auch dazu führen, dass Seiten nicht so oft wie gewünscht gecrawlt werden. Das Entfernen oder Zusammenführen von Duplicate Content kann sich daher auch positiv auf das Crawling auswirken.
- JS- und CSS-Dateien zusammenführen. Viele Webseiten verwenden mehr als eine JavaScript- und/oder CSS-Datei, um die Seite darzustellen. Für das Crawling kann es sinnvoll sein, diese Dateien in einer JS- und einer CSS-Datei zusammenzufassen.
- Nutze die Robots.txt. Mit der Robots.txt kannst du Google mitteilen, welche Bereiche deiner Website nicht gecrawlt werden sollen. Insbesondere wenn deine Website viele automatisch generierte URLs enthält, ist die Robots.txt ein geeignetes Mittel, um das Crawling zu steuern.
- Identifiziere „Crawler Traps“. Prüfe, ob es Seiten gibt, die häufig gecrawlt werden, es aber nicht sollten, weil sie für SEO keine Relevanz haben. Das geht am besten mit einer Logfile-Analyse.
💡 Status Code 503 bei der Robots.txt
Wenn die Robots.txt-Datei mit einem http-Statuscode 503 (Service Unavailable) antwortet, stoppt Google das Crawlen der gesamten Website.
Der Googlebot wird jedoch zu einem späteren Zeitpunkt erneut versuchen, die Website zu crawlen. Dies kann in Ausnahmefällen genutzt werden, um das Crawling komplett zu verhindern. In den meisten Fällen solltest du jedoch darauf achten, dass dies nicht geschieht.
Fazit
Um das Thema Crawl-Budget müssen sich vermutlich 90% der SEOs keine großen Sorgen machen. Dennoch ist es immer sinnvoll, dafür zu sorgen, dass Google und andere Suchmaschinen die Website schnell und effizient crawlen können. Wenn dies von Anfang an bei der Entwicklung der Website (technisch und inhaltlich) berücksichtigt wird, sollte es langfristig keine Probleme mit den Crawling-Ressourcen geben.
🔗 Weiterführende Links
Dokumentation von Google zum Thema
Podcast: Should I worry about crawl budget? (von Google 🇬🇧)




