Inhalt
Was ist Stable Diffusion
Stable Diffusion (SD) ist eine Open-Source-Software für Deep Learning, die hauptsächlich zur Erstellung detaillierter Bilder aus Textbeschreibungen dient. Neben Midjourney und DALL-E 3 von OpenAi das Tool um sich Bilder zu generieren.
Der große Vorteil gegenüber der Konkurrenz ist hier ganz klar, dass man das Ganze bei sich Lokal über eine App oder Programm auf dem eigenen Rechner oder auch Smartphone verwenden kann.
Wichtige Begriffe
Es gibt ein paar Begriffe die ich in diesem Beitrag verwende, die etwas kompliziert zu erklären sind – ich versuche es aber natürlich trotzdem 😊
Checkpointmodell
Hierbei handelt es sich um das trainierte Basis-Bildmodel von Stable Diffusion.
Quasi ein riesiger Wissenschatz mit extrem vielen Bildinformationen, wie zb. ein Austronaut oder ein Pferd aussieht.
Lora
Eine Möglichlichkeit das trainierte Basis-Bildmodel von Stable Diffusion mit eigenen Bildinformationen zu erweitern. Man könnte sich selbst hinzufügen und sich somit in generierte Bilder einfügen.
Prompt
Ein Prompt ist nichts anderes als eine gezielte Anweisung an die KI mit Informationen, was man genau haben möchte.

Interesse? Dann lass uns über die Möglichkeiten eines lokalen Stable Diffusion Sprechen!
Wir zeigen Dir, wie Du mit einer lokalen Installation unvergleichliche Bilder im Handumdrehen erstellst und konstant gute Ergebnisse generierst!
Was kann man mit Stable Diffusion machen?
Im Grunde kann man mit SD einfach gesagt Bilder erstellen bzw. generieren!
Und das geht überraschend einfach 🙃

Es gibt hier diverse Tools, manche sind sehr kompliziert und eher etwas für Profis, andere sind widerum sehr limitiert, liefern dafür allerdings direkt gute Ergebnisse ab.
Und das beste ist natürlich, dass diese direkt Lokal auf dem eigenen Rechner laufen und somit auch niemand die generierten Bilder zu Gesicht bekommt oder irgendetwas zensieren kann!
Programme lokal auf dem Rechner
Über die Kommandozeile bzw. Terminal:
- pinokio (1 Klick-Installation von Terminal „Apps“ / Mac & Windows)
- Automatic1111 (Mac & Windows)
- SD Forge (MAC & Windows)
- ComfyUI (Mac & Windows)
- InvokeAI (Mac & Windows)
App’s:
- DrawThings (Mac)
- DiffusionBee (Mac)
Da wir kein Windows einsetzen, kann ich hierzu keine valide Aussage treffen, eine kurze Suche ergab aber die folgenden Programme 😅
Online
- Dreamstudio.ai
- LeonardoAI
- Diffusion.to
- Dreamlike.art
- cogniwerk (deutsche Server)
- uvm.
Ressourcen
Es gibt sehr viel Content zum Thema und man kann sich hier wirklich komplett verlieren, deswegen hier auch noch ein paar Webseiten dazu:
- Stable Diffusion Art – Tutorials, prompts and resources (stable-diffusion-art.com)
- Lexica
- Civitai: The Home of Open-Source Generative AI
Wie fange ich mit Stable Diffusion an?
Wie bereits erwähnt, empfehle ich SD direkt am Rechner zu verwenden, leider braucht man hier schon etwas potentere Hardware. Das hier sind die minimalen Vorraussetzungen:
- Windows, MacOS, oder Linux
- Mac’s mit M Chips sind hier ordentlich im Vorteil!
- Grafikkarte mit min. 4GB
- AMD scheint hier nicht so richtig zu laufen (muss also individuell getestet werden)
- 15GB freien Speicher, am besten eine SSD
damit kann man Bilder mit 512×512 o. 768×768 Pixel generieren, höhere Auflösungen sind damit damit eher schwierig umzusetzen. Hier gilt also wirklich Mal: umso mehr umso besser 🤷🏻♂️
Eigenes Lora-Bildmodel trainieren
Man kann mit Stable Diffusion im Grunde alles generieren, was einem einfällt und somit sind der eigenen Fantasie keine Grenzen gesetzt. Was aber, wenn man sich selbst in diese Bilder einfügen möchte? Oder einfach tolle Portraits von sich erstellen möchte, wie dieses hier:

Was ist ein LORA-Bildmodel?
Ein LORA-Bildmodel (hier mehr dazu) kann man als Erweiterung zu einem Stable Diffusion Checkpointmodell beschreiben, mit wichtigen Informationen zu einer Person zb.:
- Augenfarbe
- Bart
- Hautfarbe
- etc. pp
Der Vorteil eines LORA’s ist vor allem, dass man nicht immer das große Stable Diffusion Checkpointmodell (ca. 6GB) trainieren muss sondern mit relativ wenig Aufwand „nur“ zusätzliche Bildinformationen (ein paar MB) zur Verfügung stellt.
Das trainieren eines Checkpointmodells ist wesentlich Aufwändiger und vor allem dauert es viel länger.

Wir trainieren ein Image Model ganz nach deinen Wünschen!
Lass uns gemeinsam besprechen, wie dir ein eigenes Image Model mit Stable Diffusion helfen kann!
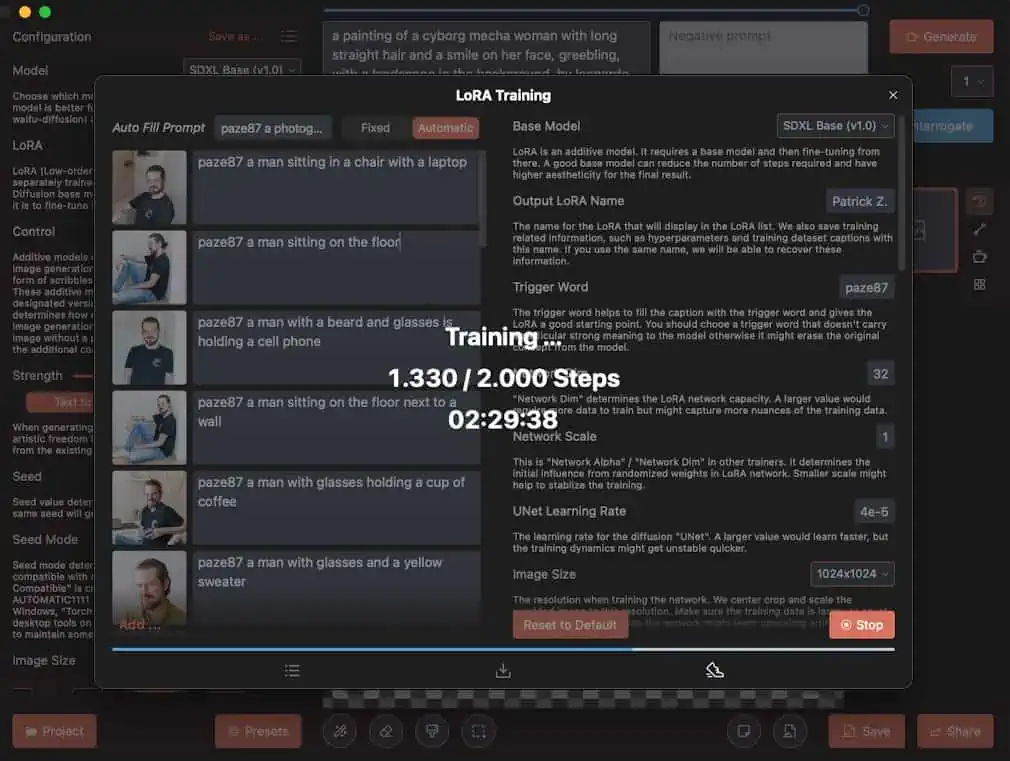
Trainieren meines eigenen LORA-Bildmodels
Ich habe für das Trainieren meines eigenen Lora-Bildmodels und zum Erstellen der Bilder die App DrawThings verwendet – diese bietet eine übersichtliche Benutzeroberfläche und sehr viele Einstellungsmöglichkeiten!
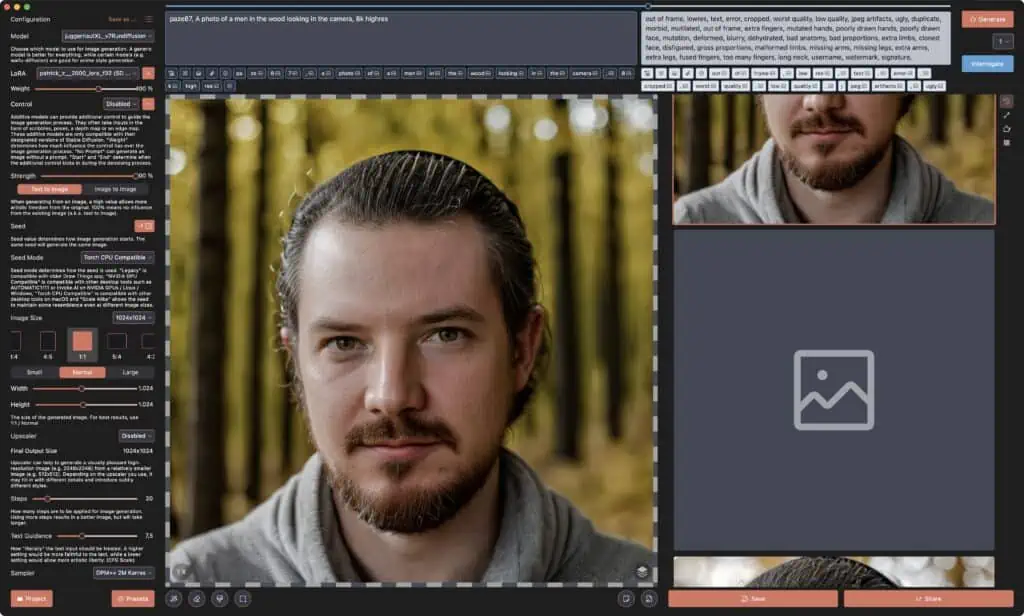
Meine Trainingsdaten waren insgesamt 26 Bilder von mir, die Bilder welche anscheinend am besten für das Training waren:



Warum ich denke, dass dies die Bilder sind, mit welcher das training des Bildmodels am besten klar kam?
Achte einmal auf den Haarreif, da waren meine Haare noch kürzer und ich musste immer mit diesem Ding rumrennen 😅 und egal wie ich den Prompt anpasse, ich komme immer mit diesem Haarreif heraus … witzigerweise auch immer ohne Brille 🤷🏻♂️
Hier ein Video zum Trainieren eines LORA direkt mit der DrawThings App.
Hier merkt man aber auch direkt, dass das Trainieren richtig Ressourcenhungrig ist! Benutzt habe ich einen M1 MAX mit 64GB RAM:
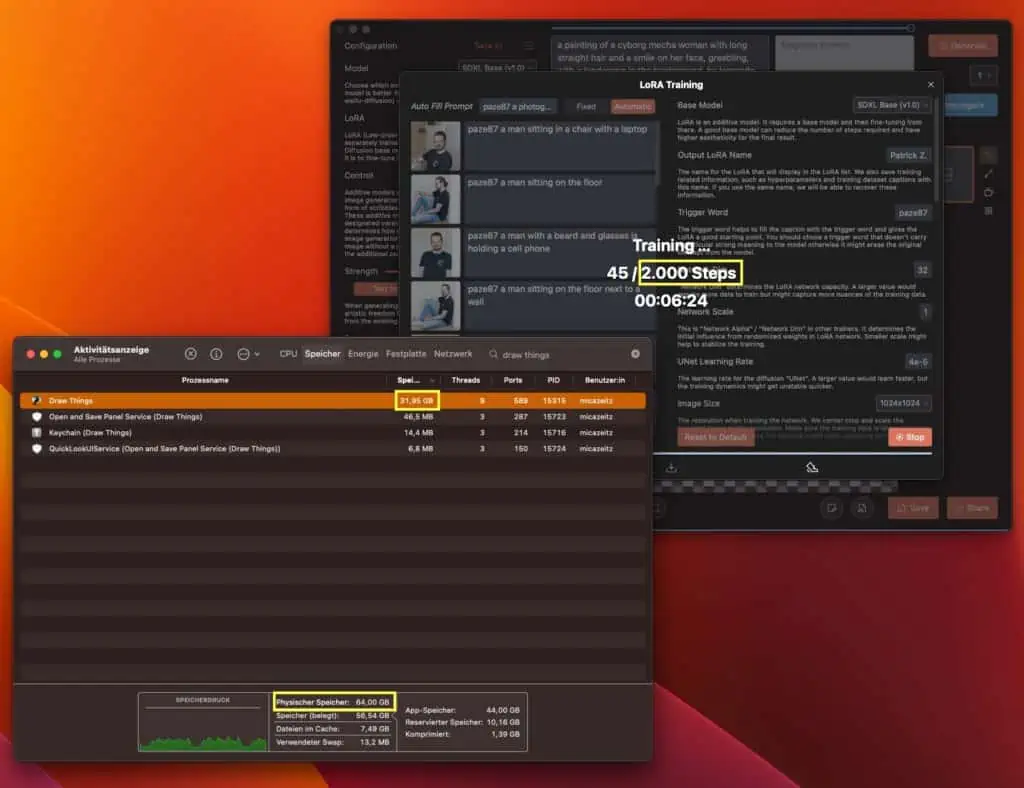
Das Training hat mit 2000 Schritten insgesamt 4 Stunden benötigt, danach konnte ich auch schon direkt loslegen und mich selber Prompten. Am Anfang mit relativ wenig Erfolg – man achte auf die Brusthaare.
Wenigstens ist aber natürlich der Haarreif vorhanden 😵💫

Und so habe ich dann einfach Step by Step weitergemacht






Nach ca. 16 Stunden Prompten und ausprobieren
Mittlerweile habe ich die für mein trainiertes Lora-Bildmodel und Checkpoint (Juggernaut mehr dazu im nächsten Abschnitt) passenden Einstellungen gefunden und bin eigtl. ziemlich zufrieden damit:



Das Lora-Bildmodel ist nur ein Teil und was ein Checkpointmodell ist
Mit dem Lora-Bildmodel habe ich eigentlich etwas vorgegriffen, denn ein LORA (Low-Rank Adaptation) ist eigtl. der 2te Schritt. Vorher benötigen wir noch ein Checkpointmodell:
Stabile Diffusionsmodelle oder Checkpoint-Modelle sind vortrainierte Modelle zur Erzeugung eines bestimmten Bildstils – schau Mal hier.
Das Checkpointmodell ist mit Millionen von Bildern und Stilen trainiert, nur so ist Stable Diffusion in der Lage aus einem sehr einfachen Prompt wie zb.:
A man stands on a bridge and looks out over a river, the sun is shining in the background and is just setting, cinematic photo photograph, Kodak portra 800, . 35mm photograph, film, bokeh, professional, 4k, highly detailed
solch ein Bild zu generieren:

Stable Diffusion Modelle
Das neueste Model ist aktuell Stable Diffusion XL Turbo, hier kann man Bilder in Echtzeit generieren.
Ich habe allerdings Stable Diffusion XL verwendet, hier gibt es ein BASE Model (sd_xl_base_1.0_0.9vae.safetensors) und das LORA dazu (sd_xl_offset_example-lora_1.0.safetensors). Damit kann man schon einmal ziemlich ordentliche Bilder generieren. Allerdings habe ich recht schnell gemerkt, dass die Bilder nicht so richtig echt aussehen – gerade die Gesichter sahen sehr „kaputt“ und unfertig aus. Deswegen bin ich auf die Suche nach anderen Modellen gegangen und bin letztlich bei „Juggernaut XL“ hängengeblieben. Dieses Bildmodel verwendet ebenfalls Stable Diffusion XL, wurde aber noch weiter trainiert und liefert wirklich beeindruckende Ergebnisse:
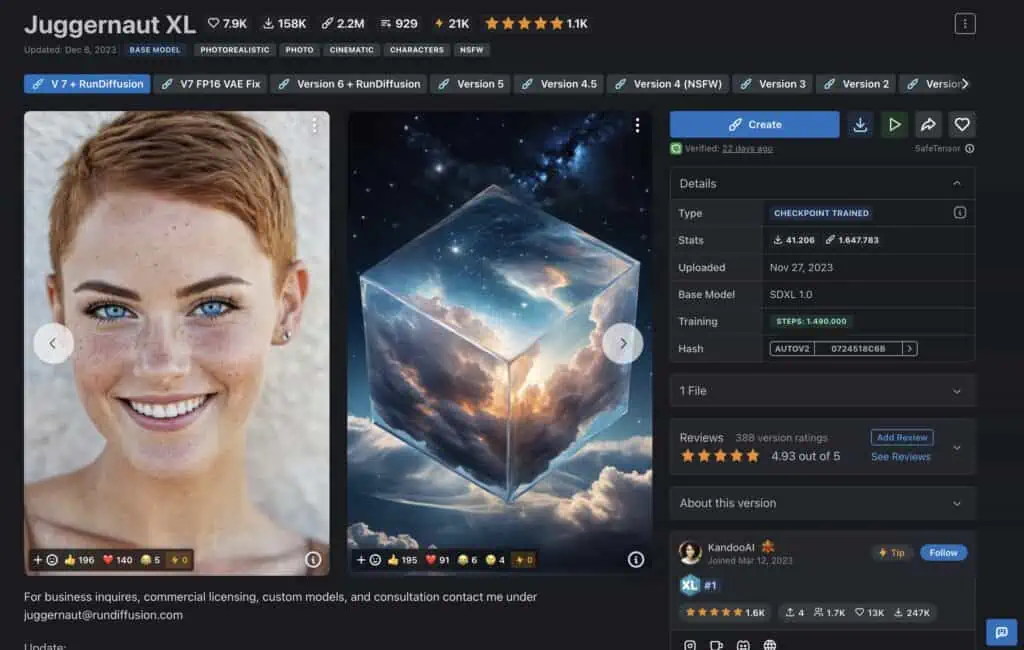
Meine Portraits wurden damit generiert!
Tipps
Es gibt ein paar Dinge zu beachten!
Negativ Prompt
Negative Prompts sorgen dafür, dass Stable Diffusion grob gesagt keinen Mist baut 😅
Als Besipiel:
out of frame, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature
Gesichter und andere Extremitäten
Es kann passieren, dass plötzlich ein Fuss oder ein Kopf aus einem Arm wächst – hört sich verrückt an, passiert aber und sieht genauso verstörend aus wie es sich liest. Hier einfach nochmal probieren und evtl. genauer beschreiben was man sehen möchte.
Bildkomposition und andere Angaben
Man sollte genau angeben was man sehen möchte zb. ein Portrait oder eine Ganzkörperaufnahme.
Eben so genau wie möglich in so kurzen Prompts wie möglich. Hier hilft dann eben auch das Negativ Prompten.
Bildeinstellungen
Ich verwende am Ende des Prompts aktuell dies hier:
cinematic photo photograph, Kodak portra 800, . 35mm photograph, film, bokeh, professional, 4k, highly detailed
damit habe ich bis jetzt die besten Ergebnisse erzielt. Aber da kann man wirklich viel selber austesten.
Fazit und Gedanken
Puhh, ganz schön viele Infos … ich weiß.
Aber glaub mir, ich habe noch gar nicht alles was in meinem Kopf rumfliegt aufgeschrieben – es ist einfach eine unfassbare Technik.
Innherhalb von so kurzer Zeit sind riesige Communitys entstanden, die immer mehr und mehr herausfinden wie man die besten Prompts schreibt. Denn eines muss man natürlich verstehen:
Wir schreiben einer KI einen Text bzw. Prompt und aus diesem soll ein Bild entstehen!
Wir haben ja aber schon eine gewisse Vorstellung des Bildes im Kopf, hier muss man sich klar machen was für eine unglaubliche Leistung es seitens der KI ist solche Bilder zu generieren!
Für mich ist absolut klar, ein menschlicher Fotograf ist nicht ersetzbar, einfach aus einem Grund:
Kreativität.
Allerdings können wir mit KI die verrücktesten Dinge anstellen und ja auch beide Welten miteinander verbinden – eben so wie es damals mit Photoshop bzw. den anfängen der digitalen Bildbearbeitung war.
Jeder dachte:
Ohje, jetzt wird alles den Bach heruntergehen, ich werde arbeitslos, weil die ja einfach alles am Rechner erstellen können.
Es ist aber genau andersherum gekommen, denn die jenigen, die sich mit der neuen Technik beschäftigt haben sind begehrte Experten geworden. Der Rest gehört irgendwann zum alten Eisen oder sticht durch seine „besondere“ Art hervor – das werden allerdings nur die wenigsten schaffen.
Für mich ist die Bildgenerierung mit Stable Diffusion und anderen Tools die Zukunft und ich rate jedem sich damit zu beschäftigen – es macht einfach Spaß zu sehen was möglich ist. Und wenn man das Ganze dann auch noch mit seinen realen Fotos von Menschen usw. kominiert wird es erst richtig Spannend.

Wie wäre es mit einem Prompt-Workshop, welcher komplett auf deine Bedürfnisse ausgerichtet ist?
Wir analysieren gemeinsam deinen Use Case und können so evidenzbasiert ein Promptsheet entwickeln, das dir deine Arbeit massiv erleichtert und dir über Jahre ein nützlicher Begleiter sein wird!
DrawThings Settings
Hier findest Du noch meine DrawThings Einstellungen
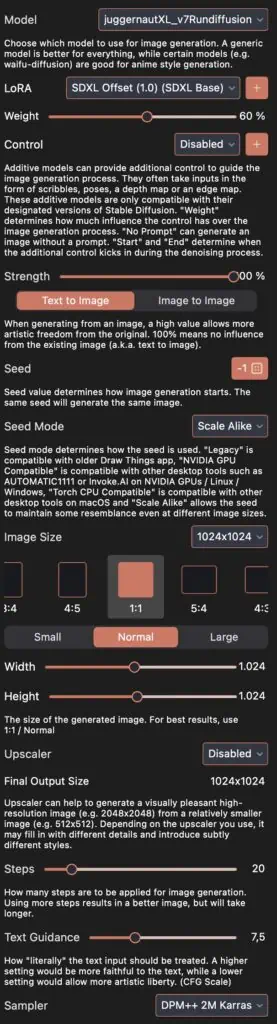

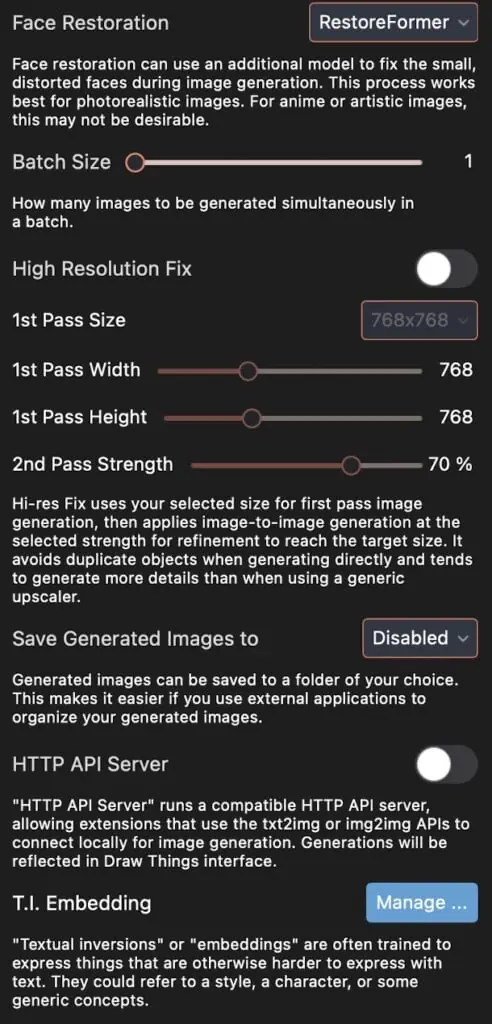
Wichtig ist noch zu Wissen, dass man natürlich immer noch etwas herumprobieren muss.
Gerade mit den Gesichtern ist es nicht so einfach. Wenn man sein eigenes LORA trainiert, dann sollte die Einstellung „Face Restoration“ deaktiviert sein – da kommt nur Unsinn raus. Und auch so muss man sehen, ob die Face Restoration nötig ist – am besten einfach ausprobieren.